
一小时kafka
简介
kafka是开源的分布式事件流处理平台
可以使用kafka作为消息中间件,将服务之间的通信和数据交换解耦,每个服务可以将自己的操作封装成一个事件,比如用户下单之后,订单服务会产生一个订单已创建事件,订单服务就是一个生产者,然后这个事件会被发送到卡夫卡中,库存 积分 支付等等其他服务就可以订阅这个事件,它们也就是消费者 Consumer,当他们准备好的时候就可以从Kafka中读取这个事件并进行处理,这种模式就是我们常说的生产者消费者模式。
一些服务作为生产者来产生事件,其他服务作为消费者来处理事件,中间的Kafka就是一个消息队列,将生产者和消费者解耦,每个事件在Kafka中都有一个唯一的序号叫做offset,用来标识事件的位置,消费者可以通过offset来跟踪已消费的事件,确保不会重复消费或者漏消费,而且这些事件会被持久化到Kafka中,即使某个服务暂时不可用也不会丢失数据,等到服务恢复后就可以从上一次的offset开始继续处理。
在实际业务中不同服务的速度可能会有差异,比如订单服务可能处理得比较快,而支付服务可能处理得比较慢,这就会导致消费者的处理速度跟不上生产者的发送速度,如果生产者一直在发送消息而消费者处理不过来,那么这些消息自然也就积压在Kafka中,既然一个消费者跟不上的话,那么就可以增加更多的消费者来处理。同样的道理 如果生产者不够快,当然也可以增加更多的生产者来发送消息。
但是新的问题来了,当有很多个生产者和消费者时,如何让消息更加有序地进行分类和组织呢,Kafka提供了一个机制:主题 Topic,也就是可以将消息按照主题来进行分类和组织,可以把主题看作是文件系统中的文件夹,而事件则是文件夹中的文件,或者也可以类比成数据库中的表,生产者可以把不同类型的消息放到不同的主题中,不同的消费者就可以订阅不同的主题,每个消费者只需要关注自己订阅的主题,然后独立地进行处理而不需要关心其他主题的消息
每个主题还可以再细分成多个partition分区,每个分区可以被不同的消费者线程并行处理,比如一个主题有10个分区,那么就可以最多有10个消费者,同时并行地来处理这个主题的消息,需要注意的是Kafka只会保证每个分区内的消息是有序的,但是不同分区之间的消息顺序是不保证的,也就是说如果有一个主题有多个分区,那么就不能保证整个主题的全局顺序,所以在设计卡夫卡的主题和分区时需要根据业务需求来合理划分,比如如果想要保证用户的交易记录是有序的,那么就可以把同一个用户的交易记录放到同一个分区里面就可以了,常用的做法是把用户ID作为分区的Key,Kafka会根据Key的哈希值来决定消息应该放到哪个分区,相同的Key也就会被放到同一个分区中

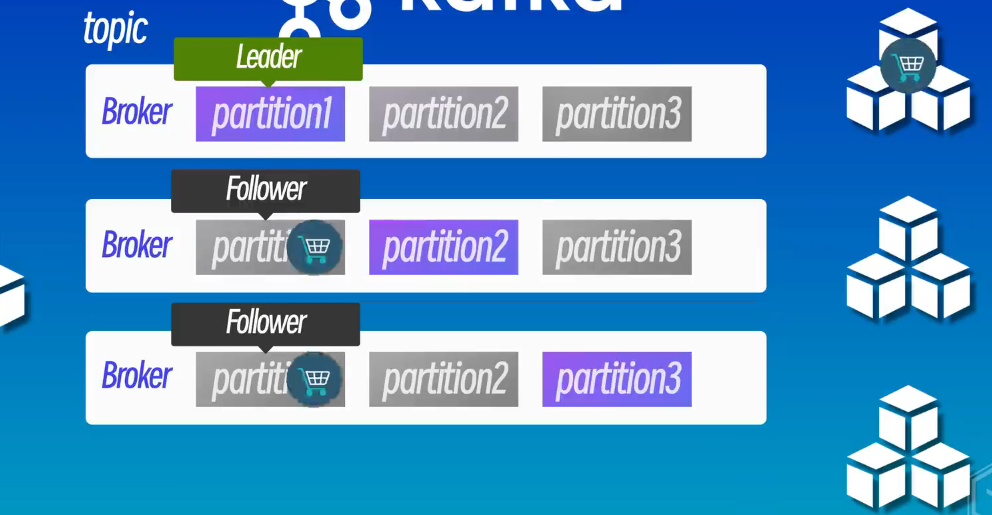
为了确保Kafka的高可用性和可靠性,Kafka集群通常由多个Broker组成,每个Broker都是一个独立的服务器,负责存储和转发消息,每个broker可以存储多个主题的多个分区,并且每个分区可以有多个副本,副本是分区的备份,每个分区有一个Leader和多个Follower,Leader负责对外处理实际的读写请求,而Follower负责复制Leader的数据,这样就可以保证即使某个Broker宕机也不会丢失数据,其他Broker上的副本可以继续对外提供服务,Kafka集群的规模可以根据业务需求进行扩展,比如可以增加更多的Broker来提高吞吐量和可用性,Kafka会自动将主题的分区分布到不同的Broker上,来实现负载均衡和高可用性
Kafka还提供了消费者组(consumer group)的概念,多个消费者可以组成一个消费者组,共同消费同一个或者多个主题的消息,有一点需要稍微注意的是每条消息只能被同一消费者组中的一个消费者消费,但是可以被多个不同的消费者组消费,这样就可以实现多种不同的消费场景,最简单和常用的使用场景就是,当多个系统或者服务需要消费同一个主题的消息时,就可以让不同的系统使用不同的消费者组,比如还是我们之前的例子,就可以把库存服务 积分服务 支付服务等分别放到不同的消费者组中,每个消费者组可以独立地消费消息和处理业务,这样即便订阅的是同一个主题,系统之间也不会互相干扰
安装
快速开始:https://kafka.apache.org/quickstart
一般不在win安装,先把下载的文件传到linux里,上传完成之后输入ls命令来查看一下确认安装包,然后使用tar命令来解压一下
1 | tar -xzvf kafka_2.13-4.1.0.tgz |
进入解压后的目录里面来看一下
1 | cd kafka_2.13-4.1.0 |
接下来需要启动Kafka服务,我们先回到官网找到快速开始这个页面https://kafka.apache.org/quickstart,首先要生成一个集群的UUID,这个UUID就是Kafka在KRatt模式引入的设计,用来唯一标识一个集群,防止不同集群的Broker之间发生冲突,执行这行命令,这样就会生成一个唯一的集群ID,并且把它保存到这个环境变量里面
1 | cd kafka_2.13-4.1.0 |
然后把第二行命令也复制粘贴执行一下
1 | bin/kafka-storage.sh format --standalone -t $KAFKA_CLUSTER_ID -c config/server.properties |
最后是启动Kafka服务的命令
1 | bin/kafka-server-start.sh config/server.properties |
最后提示Kafka Server started就说明启动成功了,然后新打开一个终端窗口,进入到Kafka的安装目录下,先来查看一下版本信息,可以看到是4.1.0,然后再来查看一下主题列表,这里大家可以先不用管这一行命令的具体含义,只需要知道这是用来查看Kafka主题列表的命令就可以了,回车之后可以看到没有任何返回,这是因为我们还没有创建任何主题
1 | cd kafka_2.13-4.1.0 |
需要注意的是kafka是基于java运行的所以需要jdk环境,尤其是对于新版的Kafka4.0.0,需要java11或者更高的版本,linux使用docker的话因为容器的隔离性,所以不能正常让kafka运行,要直接在宿主机安装java
如果需要docker安装,再去看视频,这里懒得弄了
创建和管理主题
另外我也是使用Fish Shell的简写也就是abbr功能来简化一些常用的操作,比如当我输入了ks之后就会自动补全整行命令,这样就可以快速列出所有的主题
1 | 注意这里的 kls 并不是Kafka自身的命令 |
我们先来查看一下当前都有哪些主题,在bmn目录下有一个叫做kafka-topics的脚本,这个脚本就是用来管理Kafka主题的,我们可以使用它来列出当前所有的主题,或者创建 修改和删除主题等操作都可以通过这个脚本来完成
1 | cd kafka_2.13-4.1.0 |
第一个参数表示连接到Kafka服务的地址,这里我们使用本地的Kafka服务,所以使用的是localhost;9092端口,第二个参数是-list,也就表示列出所有的主题,回车之后可以看到返回结果是空的,因为目前我们还没有创建任何主题
1 | bin/kafka-topics.sh --bootstrap-server localhost:9092 --list |
那我们先来创建一个主题,比如我们创建一个叫做mytopic的主题,就可以输入kafka-topics之后,后面还是加上表示本地服务的参数,然后再加上–create选项,最后再指定主题的名称比如就叫做my-topic,回车之后 一个主题就创建好了,可以看到提示信息Created topic my-topic.显示主题创建成功了,再次查询就显示主题了
1 | bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic |
我们也可以把-list参数换成–describe,这样就可以查看主题的详细信息,比如分区数 副本因子等等。小技巧:因为kafka指令长,所以可以在每个参数后面加上一个反斜杠,这样就可以把命令分成多行来输入,可以提高一点可读性
1 | bin/kafka-topics.sh \ |
修改主题
我们也可以对主题的设置进行一些修改,比如修改分区数 保留时间等等,还是以刚刚的my-topic主题为例,它的分区数和副本因子都是1,这里也并没有显示它的默认保留时间,默认情况下Kafka会保留消息7天,如果想要修改这个时间的话,可以使用kafka-configs这个脚本来修改主题的配置
比如把保留时间改为10秒的话,就可以输入kafka-configs之后后面加上服务器地址参数,然后再加上–entity-type topics表示我们要修改的是主题的配置,接着再加上–entityname my-topic表示我们要修改的主题名称,然后再加上一个–alter选项表示我们要修改配置,最后再加上一个–add-config和一个保留时间的参数表示我们要把保密时间设置为10秒,回车之后修改就生效了,然后再次查看主题的配置,可以看到保密时间已经被修改为10秒了,注意 这里仅仅是为了演示,实际使用中一般不会把保留时间设置得这么短,因为这样会导致消息很快就被删除了
1 | bin/kafka-configs.sh --bootstrap-server localhost:9092 --entity-type topics --entity-name my-topic --alter --add-config retention.ms=10000 |
删除主题
删除一个主题也非常简单,还是使用刚刚的kafka-topics脚本,只需要加上–delete选项,然后再使用–topic参数指定要删除的主题名称,比如我们要删除刚刚创建的my-topic主题,回车之后就会提示主题删除成功了
1 | bin/kafka-topics.sh -bootstrap-server localhost:9092 --delete --topic my-topic |
发送接收消息
接下来我们来模拟一个生产者发送一些事件到Kafka主题中,在bin目录下有一个kafka-console-producer的脚本,这个脚本可以用来发送消息到指定的Kafka主题,因为上节课创建的主题最后被删除了,所以我们还是先来创建一个,名字还是叫my-topic,主题创建好之后我们就可以使用kafka-console-producer这个命令来发送事件到刚刚创建的主题中,服务器地址使用localhost;9092,主题名是刚刚创建的my-topic,回车之后就会进入一个交互式的命令行界面
在这里我们可以输入一些事件数据,每输入一行数据都会作为一条消息发送到Kafka的my-topic主题中,比如我们可以输入一些简单的文本信息,先来输入一个欢迎来到GeekHour,然后再来个一键三连 ,输入完成之后可以使用Control+C快捷键来退出,这样我们就成功地将一些事件发送到了Kafka的主题中。
然后我们再来打开一个新的终端来读取刚刚发送的事件消息,方法是使用bin目录下的另外一个脚本,也就是kafka-console-consumer这个脚本,这个脚本可以用来消费Kafka主题中的消息,输入脚本名称之后服务器地址还是使用localhost:9092,中间加上了一个–from-beginning选项表示从主题的开头开始读取消息,如果不加这个选项的话就会从上次消费的位置开始读取,最后指定主题名是my-topic,回车之后就可以看到刚刚发送的消息了,这个时候如果我们再回到第一个终端,在生产者中继续输入新的消息那么在消费者终端中也会实时显示出来,这样就实现了生产者和消费者之间的实时消息传递
1 | bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic |
这个示例只是让大家对于Kafka有个直观的了解,实际使用中我们一般不会直接在命令行中来发送和消费消息,而是会使用编码的方式来操作Kafka
GUI工具
图形化工具:Offset Explorer : https://kafkatool.com/,也就是之前的Kafka Tool,它是一个跨平台的Kafka管理工具,可以帮助我们可视化地管理Kafka集群 主题和消费者,这里不多做演示,可以看视频
在程序中使用kafka
首先是前端最经常使用的javaScript,在前端NodeJS环境中可以很方便地同Kafka进行交互,可以使用一些现成的库来实现Kafka的Producer和Consumer,比如使用KafkajS,它是一个纯javaScript编与的Kafka客户端库,可以通过API的方式来提供Kafka的Producer和Consumer功能,包括发送和接收消息,并且提供了简单易用的API接口可以很方便地集成到NodeS应用程序中,KafkaS是一个开源项目,可以在GitHub上找到它的源代码和文档
首先需要创建一个新的NodeJS项目,打开一个终端之后先来创建一个文件夹比如就叫做kafka-js-demo,然后进入到这个文件夹里面,输入pnpmintt 命令来初始化一个新的NodeJS项目,这个命令会创建一个package.json文件,文件里面包含了项目的基本信息和依赖关系,我个人比较习惯使用pnpm来管理前端NodeJS的项目,当然使用其他的包管理器比如npm或者yamn也是没有问题的
接下来还需要安装一个KafkaJS库,执行 pnpm install kafkajs 命令,在命令行使用code命令来在VSCode中打开这个文件夹,这里的点号表示当前目录,-r表示在当前窗口打开,当然使用Cursor也是OK的,然后新建一个js文件比如叫做producer.js,负责发送消息到Kafka。小技巧:使用cursor可以先输入一些简单的注释来提示AI你想要实现的功能,比如这里我们在文件的第一行输入一个//kafka producer example,这样cursor就会根据这个提示来自动补全代码,首先需要引入KafkaJS库,然后创建一个Kafka客户端实例,最后创建一个发送消息的函数,并且调用它来发送消息到Kafka,第一个参数表示主题的名称也就是我们之前创建的my-topic,第二个参数是消息内容就直接使用它自动生成的内容就可以,这样这个Producer文件就完成了
1 | mkdir kafka-js-demo |
1 | // kafka producer example |
保存一下这个文件,然后在下面的终端里面输入node加上这个文件名来执行一下,回车之后可以看到提示我们消息发送成功了
1 | cd F:\kafka-js-demo |
接下来我们再来创建一个消费者来接收这个消息,创建一个consumer.js的消费者文件,同样先来添加一行//kafka consumer example的注释来补全代码,同样需要先引入KafkaJS库,然后创建一个Kafka客户端实例,接着创建一个消费者函数,最后还需要调用一下这个函数来接收消息,然后保存一下这个文件
1 | // kafka consumer example |
再打开一个终端使用命令行工具看一下,先来进入到Kafka的安装目录看一下有哪些主题,这里多了一个-consumer offsets的主题,这是Kafka内部使用的一个主题,用来存储消费者的偏移量信息,一般不需要太关注它,然后使用命令来接收一下消息,回车之后可以看到在producer,js中发送的消息也已经被接收到了,这就说明我们的JavaScript代码成功地与Kafka进行了交互
1 | cd kafka_2.13-4.1.0 |
搭建使用kafka集群
接下来我们将会搭建一个包含三个Broker的Kafka集群,每个Broker都运行在独立的Docker容器中,我们将使用Docker Compose来简化容器的管理和配置,还会启动一个Kafka Ul界面工具来方便我们进行集群的管理和监控。

先来创建一个Docker网络用来让Kafka的容器之间可以互相通信,创建Docker网络的命令是dockernetwork create,后面加上网络的名称和子网地址就可以了,然后再来创建一个文件夹用来存储Kafka集群的配置文件和数据,在这个目录下再分别创建三个子目录,分别用来存储每个Broker的数据,比如就叫做kafka1 2和3
接下来还需要创建一个DockerCompose文件来定义Kafka集群的配置,这里我们已经提前准备好了一个Docker Compose文件,我们稍微来解释一下这个文件的内容,networks这里定义了一个叫做kafka-net的Docker网络,其实如果这里定义了的话那刚刚我们手动创建网络的那个步骤是可以省略的,因为待会我们执行DockerCompose的时候也会自动帮我们创建这个网络,不过事先创建好也是可以的
然后下面的service部分就分别定义了三个Kafka Broker和一个kafika UI服务,第一个kafka1服务将9092和9093端口正常映射到宿主机,下面使用volumes将本地电脑中的/kafkal/data目录挂载到了容器中的/var/lib/kafka/data目录,这样就可以将Kafka容器中的数据持久化到本地文件系统中,即使容器重启或者被删除,数据也仍然会保留在本地不会丢失。再下面就是使用了刚刚定义的kafka-net网络,下面的Kafka2和KafKa3服务也是类似的配置,唯一不同的是端口号和数据目录,Kafka2服务将端口映射到宿主机的9094和9095端口
还有下面的数据挂载位置也是/kafka2下面的data目录,Kafka3服务也是一样的,端口映射到了9096和9097,挂载位置是kafka3下面的data目录,最后还有一个Kafka UI服务,是一个Web界面工具,端口是8080,用来管理和监控Kafka集群,它依赖于上面定义的三个Kafka Broker服务和kafka-net网络,这就是这个Kafka配置文件的基本内容
保存退出之后回到命令行,输入DockerCompose之后后面加上-f指定这个配置文件,然后再加上up参数和-d选项之后回车,就会在后台启动所有的Kafka Broker和Kafka U容器
1 | sudo docker network create kafka-net --subnet 172.20.0.0/16 |
我们可以使用docker compose后面加上-f参数和配置文件的名称,然后再加上一个ps来查看Kafka集群的状态,这个命令将会显示所有容器的状态确保所有的Kafka Broker都在运行,然后打开一个浏览器在地址栏输入localhost:8080就可以打开一个Kafka ul界面,在这里我们可以看到所有的Broker主题 消费者组等信息,还可以创建新的主题
1 | sudo docker compose -f docker-compose.yml ps |
Kafka集群启动之后也可以创建或者查看一个主题,不过因为是使用Docker来运行的,所以命令前面我们需要加上 docker exec来执行Kafka的命令行工具,我们可以使用下面的命令来创建一个主题,这里的replication-factor参数表示主题的副本数,partitions参数表示主题的分区数,也可以使用list参数来查看所有的主题,可以看到一个叫做my-topic的主题就被创建好了
1 | docker exec it kafkal kafka-topics \ |





